What is Vector Embedding
Embedding Models and Vector Formats:

- Embedding models are specialized tools that convert various filetypes (documents, images, videos, etc.) into vector formats.
- The output is an array of floating-point numbers with a fixed length (e.g., 768, 1536, or any number) that specifies the coordinate of the new data in the dimensional space.
- The array length defines the dimensional space
- e.g., 200 means a 200-dimensional space.
- In this space, a vector’s position and its nearby surroundings encode semantic meaning, allowing you to identify content with similar intent or context.
- The array length defines the dimensional space
- What do the numbers mean?
- Reference What do the number mean
- Elements of the vector implicitly or explicitly correspond to specific features or attributes of the object.
- For example,
- In an image recognition system, a vector could represent an image, with each element of the vector representing a pixel value or a descriptor/characteristic of that pixel.
- In a music recommendation system, each vector could represent a song, and elements of the vector would capture song characteristics such as tempo, genre, lyrics, and so on
- Core Concept: Embeddings work by taking a piece of content (text, image, video, etc.) and transforming it into this array of numbers, capturing its essence in a machine-readable form.
Similarity Search with Embeddings:
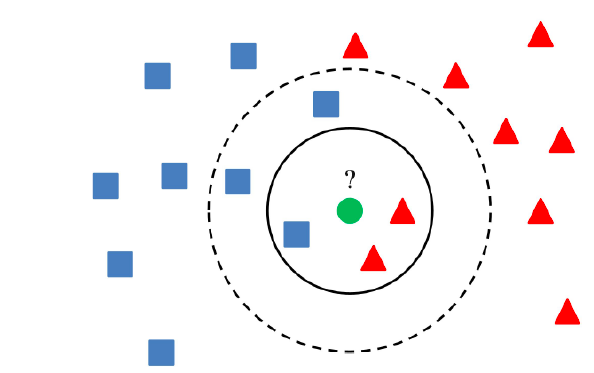
- When performing a similarity search, don’t expect exact phrase matches with your query. Instead, anticipate results that are semantically similar but may not contain the same wording.
- Example: Searching "SQLite backup tools" in an embedding set might not return a row with the word "backup," but rather content that aligns with the concept or "vibe" of backups (semantic search).
Functionalities Enabled by Embeddings:
- Semantic Search:
- Search for text, documents, images, etc., based on meaning, related concepts, or "vibe."
- Recommendation systems:
- For example, We populate the vector store with items information such name, description and other important detail then when a user makes an interest on certain item we do k-nearest search on the store, further optimization can be made in that, instead of just relying on the current user item metadata, we also consider user's previous interaction histories
- Improving Recommendation Systems & Search in the Age of LLMs
- Clustering:
- Group similar items together based on their vector proximity.
- Classification:
- Determine if an item belongs to category A or B by comparing its vector to known sets.
Why Not Use a Custom Fine-Tuned Model?
- Why Not Use a Custom Fine-Tuned Model Instead of Embeddings or RAG
- Pros of Fine-Tuning: A custom fine-tuned model can be tailored to your specific needs and kept private.
- Cons of Fine-Tuning:
- It’s expensive and technically complex to implement.
- As general models improve over time, repeatedly fine-tuning becomes unnecessary and inefficient.
- Advantages of RAG: RAG is comparatively cheaper, simpler, and leverages embeddings to achieve similar goals without the overhead of fine-tuning.
Why Convert to Vector Format?
- Vectors enable semantic search and the ability to find similar items using mathematical functions like cosine similarity.
- This format unlocks advanced search capabilities that go beyond keyword matching, focusing on meaning and relationships within the content.
Where to Look for Embedding Models?
- There are many embedding models, such as ones dedicated to text embedding, image and audio embedding also there are multimodal embedding that are capable of embedding multiple formats.
- Text embedding:
Word2Vec, Sentence Transformers(all-MiniLM), OpenAI Embeddings(text-embedding-ada-002)- Need to check if they support only english words or if they are multilingual
- MultiModal embedding:
- OpenAI(CLIP), OpenClip(open source version from CLIP)
- Jina CLIP v2: Multilingual Multimodal Embeddings for Texts and Images
- ImageBind: One Embedding Space To Bind Them All
- More notes:
- Images can be turned to text using Vision to language transformation models and them combined with text embedding.
- Some vector stores comes with their own builtin embedding models that support text and images.
- Text embedding:
- Embedding Leaderboard
Vector Databases
- Vector DB Comparison
- TLDR: Open-source locally testable vector databases, in-order from highest Github start to lowest
- Purpose build vector databases
- milvus-io/milvus: Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search
- qdrant/qdrant: Qdrant - High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI. Also, available in the cloud https://cloud.qdrant.io/
- chroma-core/chroma: the AI-native open-source embedding database
- Sqlite based and in memory db
- Traditional databases with vector indices support
- pgvector/pgvector: Open-source vector similarity search for Postgres
- MongoDB, ElasticSearch, Redis all appear to support vector storage and similarity search
- Purpose build vector databases
- TLDR: Open-source locally testable vector databases, in-order from highest Github start to lowest